题目描述
一个文件目录的数据格式为:目录id,本目录中文件大小,(子目录id列表)。
其中目录id全局唯一,取值范围[1, 200],本目录中文件大小范围[1, 1000],子目录id列表个数[0,10]例如 : 1 20 (2,3) 表示目录1中文件总大小是20,有两个子目录,id分别是2和3
现在输入一个文件系统中所有目录信息,以及待查询的目录 id ,返回这个目录和及该目录所有子目录的大小之和。
输入描述
第一行为两个数字M,N,分别表示目录的个数和待查询的目录id,
- 1 ≤ M ≤ 100
- 1 ≤ N ≤ 200
接下来M行,每行为1个目录的数据:
目录id 本目录中文件大小 (子目录id列表)
子目录列表中的子目录id以逗号分隔。
输出描述
待查询目录及其子目录的大小之和
用例
| 输入 | 3 1 3 15 () 1 20 (2) 2 10 (3) |
| 输出 | 45 |
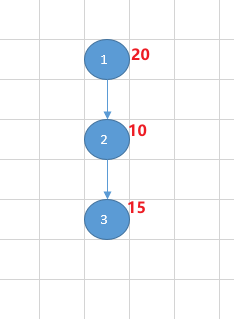
| 说明 | 目录1大小为20,包含一个子目录2 (大小为10),子目录2包含一个子目录3(大小为15),总的大小为20+10+15=45 |
| 输入 | 4 2 4 20 () 5 30 () 2 10 (4,5) 1 40 () |
| 输出 | 60 |
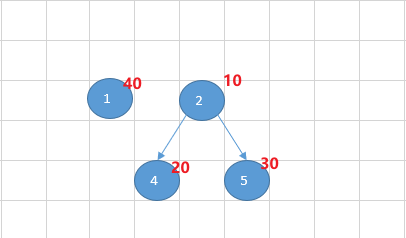
| 说明 | 目录2包含2个子目录4和5,总的大小为10+20+30 = 60 |
题目解析
用例1图示:
用例2图示:
本题的目录与子目录的关系,可以看出是一棵树,而计算某个目录及其子目录的文件大小总和,其实就是遍历某个节点下所有分支。
因此,本题可以使用深度优先搜索dfs来解决。下面代码中深度优先搜索,是基于栈实现的,而不是基于递归。基于栈实现dfs的好处是,可以避免较深递归产生的执行栈溢出。
Java算法源码
import java.util.*;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int m = sc.nextInt();
int n = sc.nextInt();
HashMap<Integer, ArrayList<Integer>> children = new HashMap<>();
HashMap<Integer, Integer> cap = new HashMap<>();
for (int i = 0; i < m; i++) {
int fa_id = sc.nextInt();
int fa_cap = sc.nextInt();
children.putIfAbsent(fa_id, new ArrayList<>());
cap.putIfAbsent(fa_id, fa_cap);
String ch_str = sc.next();
if (ch_str.length() > 2) {
children
.get(fa_id)
.addAll(
Arrays.stream(ch_str.substring(1, ch_str.length() - 1).split(","))
.map(Integer::parseInt)
.collect(Collectors.toList()));
}
}
System.out.println(getResult(children, cap, n));
}
public static int getResult(
HashMap<Integer, ArrayList<Integer>> children, HashMap<Integer, Integer> cap, int target) {
int ans = 0;
LinkedList<Integer> stack = new LinkedList<>();
stack.add(target);
while (stack.size() > 0) {
Integer id = stack.removeLast();
if (!cap.containsKey(id)) continue;
ans += cap.get(id);
stack.addAll(children.get(id));
}
return ans;
}
}
JS算法源码
/* JavaScript Node ACM模式 控制台输入获取 */
const readline = require("readline");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
const lines = [];
let m, n;
rl.on("line", (line) => {
lines.push(line);
if (lines.length == 1) {
[m, n] = lines[0].split(" ").map(Number);
}
if (m && lines.length == m + 1) {
lines.shift();
const children = new Map();
const cap = new Map();
lines.forEach((s) => {
let [fa_id, fa_cap, ch_list_str] = s.split(" ");
fa_id = Number(fa_id);
fa_cap = Number(fa_cap);
children.set(fa_id, []);
cap.set(fa_id, fa_cap);
if (ch_list_str.length > 2) {
children.get(fa_id).push(
...ch_list_str
.substring(1, ch_list_str.length - 1)
.split(",")
.map(Number)
);
}
});
console.log(getResult(children, cap, n));
lines.length = 0;
}
});
function getResult(children, cap, target) {
let ans = 0;
const stack = [];
stack.push(target);
while (stack.length > 0) {
const id = stack.pop();
if (cap.get(id) === undefined) continue;
ans += cap.get(id);
stack.push(...children.get(id));
}
return ans;
}
Python算法源码
# 输入获取
m, n = map(int, input().split())
children = {}
cap = {}
for _ in range(m):
fa_id, fa_cap, ch_str = input().split()
children[fa_id] = []
cap[fa_id] = int(fa_cap)
if len(ch_str) > 2:
children[fa_id].extend(ch_str[1:-1].split(","))
# 算法入口
def getResult(target):
ans = 0
stack = [target]
while len(stack) > 0:
id = stack.pop()
if cap.get(id) is None:
continue
ans += cap[id]
stack.extend(children[id])
return ans
# 算法调用
print(getResult(str(n)))
免责声明:
1、IT资源小站为非营利性网站,全站所有资料仅供网友个人学习使用,禁止商用
2、本站所有文档、视频、书籍等资料均由网友分享,本站只负责收集不承担任何技术及版权问题
3、如本帖侵犯到任何版权问题,请立即告知本站,本站将及时予与删除下载链接并致以最深的歉意
4、本帖部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责
5、一经注册为本站会员,一律视为同意网站规定,本站管理员及版主有权禁止违规用户
6、其他单位或个人使用、转载或引用本文时必须同时征得该帖子作者和IT资源小站的同意
7、IT资源小站管理员和版主有权不事先通知发贴者而删除本文