题目描述
误码率是最常用的数据通信传输质量指标。它可以理解为“在多少位数据中出现一位差错”。
移动通信网络中的误码率主要是指比特误码率,其计算公式如下: 比特误码率=错误比特数/传输总比特数,
为了简单,我们使用字符串来标识通信的信息,一个字符错误了,就认为出现了一个误码
输入一个标准的字符串,和一个传输后的字符串,计算误码率
字符串会被压缩,
例:“2A3B4D5X1Z”表示"AABBBDDDDXXXXXZ"
用例会保证两个输入字符串解压后长度一致,解压前的长度不一定一致
每个生成后的字符串长度<100000000。
输入描述
两行,分别为两种字符串的压缩形式。
每行字符串 (压缩后的) 长度<100000
输出描述
一行,错误的字等数量/展开后的总长度
备注
注意:展开后的字符串不含数字
用例
| 输入 | 3A3B 2A4B |
| 输出 | 1/6 |
| 说明 | 无 |
| 输入 | 5Y5Z 5Y5Z |
| 输出 | 0/10 |
| 说明 | 无 |
| 输入 | 4Y5Z 9Y |
| 输出 | 5/9 |
| 说明 | 无 |
题目解析
本题最简单的做法就是将压缩字符串解压,然后利用一次for循环,对比两个等长的压缩字符串,看有多少个位置的字符不相同。
但是本题解压后的字符串,最大长度为1 0000 0000,这个数量级对于O(n)时间复杂度来说也会超时。
另外,解压后的字符串,内存会占到 1 0000 0000 * 1 byte ≈ 96M, 两个字符串就是将近200M,这种方案在内存上也是不友好的。
因此,我们不应该优先考虑上面方案,而是应该考虑基于压缩字符串找不同字符数量。
我的解题思路如下:
定义两个变量diff和same,分别用于记录输入的两个字符串中不同字符的数量,以及相同字符的数量。
以用例1举例:

我们可以比较s1,s2的头部压缩字符串,其中,
- s1的头部压缩字符串是3A
- s2的头部压缩字符串是2A
压缩字符串由两部分组成:压缩次数num + 压缩字符c
- s1的头部压缩字符串是3A,即num1 = 3,c1 = 'A'
- s2的头部压缩字符串是2A,即num2 = 2,c2 = 'A'
当前s1,s2的头部压缩字符串是不等长的,因此我们应该取二者最小长度作为比对长度,即
compareCount = min(num1, num2)
- 如果c1 == c2的话,则compareCount就是相同字符数量,即same += compareCount
- 如果c1 != c2的话,则compareCount就是不同字符数量,即diff += compareCount
之后,继续检查num1, num2的大小关系,如果二者不等的话:
- 如果 num1 > num2,则说明s1的头部压缩字符串没有用完,我们应该将剩余部分重新退回s1头部,即将 (num1 – num2) + c1 拼接回 s1头部
- 如果 num1 < num2,则说明s2的头部压缩字符串没有用完,我们应该将剩余部分重新退回s2头部,即将 (num2 – num1) + c2 拼接回 s2头部
然后,s1,s2变为了
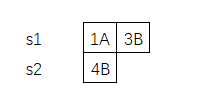
然后继续,按照上面逻辑处理,直到s1或s2为空。
当然,为了避免频繁的字符串操作,我们可以将s1,s2解析为灵活度更高的链表,链表节点元素即为压缩字符串转化的对象,类似于下面这种
{
num: 3,
c: 'A'
}
JS算法源码
/* JavaScript Node ACM模式 控制台输入获取 */
const readline = require("readline");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
const lines = [];
rl.on("line", (line) => {
lines.push(line);
if (lines.length == 2) {
console.log(getResult(lines[0], lines[1]));
lines.length = 0;
}
});
function getResult(s1, s2) {
const link1 = getZipStrLink(s1);
const link2 = getZipStrLink(s2);
let diff = 0;
let same = 0;
while (link1.length > 0) {
const [num1, c1] = link1.shift();
const [num2, c2] = link2.shift();
const compareCount = Math.min(num1, num2);
if (c1 != c2) {
diff += compareCount;
} else {
same += compareCount;
}
if (num1 > num2) {
link1.unshift([num1 - num2, c1]);
} else if (num1 < num2) {
link2.unshift([num2 - num1, c2]);
}
}
return `${diff}/${diff + same}`;
}
function getZipStrLink(s) {
const link = [];
const num = [];
for (let i = 0; i < s.length; i++) {
const c = s[i];
if (c >= "0" && c <= "9") {
num.push(c);
} else {
const zipStr = [parseInt(num.join("")), c];
link.push(zipStr);
num.length = 0;
}
}
return link;
}
Java算法源码
import java.util.LinkedList;
import java.util.Scanner;
public class Main {
static class ZipStr {
int num;
char c;
public ZipStr(int num, char c) {
this.num = num;
this.c = c;
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String s1 = sc.nextLine();
String s2 = sc.nextLine();
System.out.println(getResult(s1, s2));
}
public static String getResult(String s1, String s2) {
LinkedList<ZipStr> link1 = getZipStrLink(s1);
LinkedList<ZipStr> link2 = getZipStrLink(s2);
int diff = 0;
int same = 0;
while (link1.size() > 0) {
ZipStr zipStr1 = link1.removeFirst();
ZipStr zipStr2 = link2.removeFirst();
int compareCount = Math.min(zipStr1.num, zipStr2.num);
if (zipStr1.c != zipStr2.c) {
diff += compareCount;
} else {
same += compareCount;
}
if (zipStr1.num > compareCount) {
zipStr1.num -= compareCount;
link1.addFirst(zipStr1);
continue;
}
if (zipStr2.num > compareCount) {
zipStr2.num -= compareCount;
link2.addFirst(zipStr2);
}
}
return diff + "/" + (diff + same);
}
public static LinkedList<ZipStr> getZipStrLink(String s) {
LinkedList<ZipStr> link = new LinkedList<>();
StringBuilder num = new StringBuilder();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c >= '0' && c <= '9') {
num.append(c);
} else {
link.add(new ZipStr(Integer.parseInt(num.toString()), c));
num = new StringBuilder();
}
}
return link;
}
}
Python算法源码
# 输入获取
s1 = input()
s2 = input()
def getZipStrLink(s):
link = []
num = []
for i in range(len(s)):
c = s[i]
if c.isdigit():
num.append(c)
else:
link.append([int("".join(num)), c])
num.clear()
return link
# 算法入口
def getResult():
link1 = getZipStrLink(s1)
link2 = getZipStrLink(s2)
diff = 0
same = 0
while len(link1) > 0:
num1, c1 = link1.pop(0)
num2, c2 = link2.pop(0)
compareCount = min(num1, num2)
if c1 != c2:
diff += compareCount
else:
same += compareCount
if num1 > num2:
link1.insert(0, [num1 - num2, c1])
elif num1 < num2:
link2.insert(0, [num2 - num1, c2])
return f"{diff}/{diff + same}"
# 算法调用
print(getResult())C算法源码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_SIZE 100000
#define MIN(a, b) (a) < (b) ? (a) : (b)
typedef struct {
int num;
char c;
} ZipStr;
typedef struct ListNode {
ZipStr *ele;
struct ListNode *next;
} Node;
typedef struct List {
Node *head;
Node *tail;
int size;
} LinkedList;
char s1[MAX_SIZE];
char s2[MAX_SIZE];
LinkedList *new_LinkedList();
void addFirst_LinkedList(LinkedList *link, ZipStr *ele);
void addLast_LinkedList(LinkedList *link, ZipStr *ele);
ZipStr *removeFirst_LinkedList(LinkedList *link);
LinkedList *getZipStrLink(char *s);
int main() {
gets(s1);
gets(s2);
LinkedList *link1 = getZipStrLink(s1);
LinkedList *link2 = getZipStrLink(s2);
int diff = 0;
int same = 0;
while (link1->size > 0) {
ZipStr *zipStr1 = removeFirst_LinkedList(link1);
ZipStr *zipStr2 = removeFirst_LinkedList(link2);
int compareCount = MIN(zipStr1->num, zipStr2->num);
if (zipStr1->c != zipStr2->c) {
diff += compareCount;
} else {
same += compareCount;
}
if (zipStr1->num > compareCount) {
zipStr1->num -= compareCount;
addFirst_LinkedList(link1, zipStr1);
}
if (zipStr2->num > compareCount) {
zipStr2->num -= compareCount;
addFirst_LinkedList(link2, zipStr2);
}
}
char res[1000];
sprintf(res, "%d/%d", diff, diff + same);
printf("%s", res);
return 0;
}
LinkedList *getZipStrLink(char *s) {
LinkedList *link = new_LinkedList();
char num[100] = {'�'};
for (int i = 0; i < strlen(s); i++) {
if (s[i] >= '0' && s[i] <= '9') {
strcat(num, (char[]) {s[i], '�'});
} else {
ZipStr *ele = (ZipStr *) malloc(sizeof(ZipStr));
ele->num = atoi(num);
ele->c = s[i];
memset(num, '�', 100);
addLast_LinkedList(link, ele);
}
}
return link;
}
LinkedList *new_LinkedList() {
LinkedList *link = (LinkedList *) malloc(sizeof(LinkedList));
link->head = NULL;
link->tail = NULL;
link->size = 0;
return link;
}
void addFirst_LinkedList(LinkedList *link, ZipStr *ele) {
Node *node = (Node *) malloc(sizeof(Node));
node->ele = ele;
node->next = NULL;
if (link->size == 0) {
link->head = node;
link->tail = node;
} else {
Node *oldHead = link->head;
link->head = node;
link->head->next = oldHead;
}
link->size++;
}
void addLast_LinkedList(LinkedList *link, ZipStr *ele) {
Node *node = (Node *) malloc(sizeof(Node));
node->ele = ele;
node->next = NULL;
if (link->size == 0) {
link->head = node;
link->tail = node;
} else {
link->tail->next = node;
link->tail = node;
}
link->size++;
}
ZipStr *removeFirst_LinkedList(LinkedList *link) {
if (link->size > 0) {
Node *removed = link->head;
if (link->size == 1) {
link->head = NULL;
link->tail = NULL;
} else {
link->head = link->head->next;
}
link->size--;
ZipStr *zipStr = (ZipStr *) malloc(sizeof(ZipStr));
zipStr->num = removed->ele->num;
zipStr->c = removed->ele->c;
free(removed);
return zipStr;
}
return NULL;
}免责声明: