题目描述
某个产品的RESTful API集合部署在服务器集群的多个节点上,近期对客户端访问日志进行了采集,需要统计各个API的访问频次,根据热点信息在服务器节点之间做负载均衡,现在需要实现热点信息统计查询功能。
RESTful API是由多个层级构成,层级之间使用 / 连接,如 /A/B/C/D 这个地址,A属于第一级,B属于第二级,C属于第三级,D属于第四级。
现在负载均衡模块需要知道给定层级上某个名字出现的频次,未出现过用0表示,实现这个功能。
输入描述
第一行为N,表示访问历史日志的条数,0 < N ≤ 100。
接下来N行,每一行为一个RESTful API的URL地址,约束地址中仅包含英文字母和连接符 / ,最大层级为10,每层级字符串最大长度为10。
最后一行为层级L和要查询的关键字。
输出描述
输出给定层级上,关键字出现的频次,使用完全匹配方式(大小写敏感)。
用例
| 输入 | 5 /huawei/computing/no/one /huawei/computing /huawei /huawei/cloud/no/one /huawei/wireless/no/one 2 computing |
| 输出 | 2 |
| 说明 | 在第二层级上,computing出现了2次,因此输出2 |
| 输入 | 5 /huawei/computing/no/one /huawei/computing /huawei /huawei/cloud/no/one /huawei/wireless/no/one 4 two |
| 输出 | 0 |
| 说明 | 存在第四层级的URL上,没有出现two,因此频次是0 |
题目解析
本题应该就是一个逻辑模拟题,以及考察集合的应用。
本题的难度主要在于数据结构的定义,我们需要按照下图所示方式,对各层级的关键字进行统计
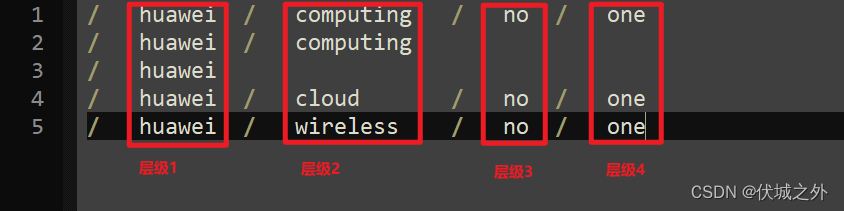
[
{}, // 层级0
{"huawei": 5}, // 层级1
{"computing": 2,"cloud": 1,"wireless": 1}, // 层级2
{"no": 3}, // 层级3
{"one": 3} // 层级4
]
外层是一个数组(数组索引就是层级号),数组元素是一个map结构(key是关键字,val是关键字在对应层级出现次数)
我们按照这种数据结构收集各条日志URL的组成关键字,就能快速的找到指定层级(通过数组索引)下的指定关键字(通过map结构的key)的出现频次(map结构的val)
更多细节信息,请看代码注释。
JS算法源码
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void (async function () {
// 访问历史日志的条数
const n = parseInt(await readline());
// 记录各层级上各关键字出现的频次
const cnts = [];
// 遍历历史日志
for (let i = 0; i < n; i++) {
// 将日志按照 "/" 分割,注意split函数会将 "/a/b/c" 会分割出数组 ["", "a", "b", "c"],因此a,b,c的层级就是其索引值
const urlComponents = (await readline()).split("/");
// 遍历url的各层级
for (let level = 0; level < urlComponents.length; level++) {
const urlComponent = urlComponents[level];
// 如果cnts不存在对于层级
if (cnts.length <= level) {
// 则创建对应层级
cnts.push({});
}
// 在对应层级上将对应关键字出现次数+1
if (cnts[level][urlComponent]) {
cnts[level][urlComponent] += 1;
} else {
cnts[level][urlComponent] = 1;
}
}
}
// 要查询的给定层级, 要查询的关键字
let [tar_level, tar_urlComponent] = (await readline()).split(" ");
tar_level = parseInt(tar_level);
if (tar_level >= cnts.length) {
// 如果要查询的层级超出了统计范围,则返回0
console.log(0);
} else {
// 获取对应层级上对应关键字出现的频次,如果没有出现,则返回0
if (cnts[tar_level][tar_urlComponent]) {
console.log(cnts[tar_level][tar_urlComponent]);
} else {
console.log(0);
}
}
})();
Java算法源码
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 访问历史日志的条数
int n = sc.nextInt();
// 记录各层级上各关键字出现的频次
ArrayList<HashMap<String, Integer>> cnts = new ArrayList<>();
// 遍历历史日志
for (int i = 0; i < n; i++) {
// 将日志按照 "/" 分割,注意split函数会将 "/a/b/c" 会分割出数组 ["", "a", "b", "c"],因此a,b,c的层级就是其索引值
String[] urlComponents = sc.next().split("/");
// 遍历url的各层级
for (int level = 0; level < urlComponents.length; level++) {
String urlComponent = urlComponents[level];
// 如果cnts不存在对于层级
if (cnts.size() <= level) {
// 则创建对应层级
cnts.add(new HashMap<>());
}
// 获取对应层级
HashMap<String, Integer> map = cnts.get(level);
// 在对应层级上将对应关键字出现次数+1
map.put(urlComponent, map.getOrDefault(urlComponent, 0) + 1);
}
}
// 要查询的给定层级
int tar_level = sc.nextInt();
// 要查询的关键字
String tar_urlComponent = sc.next();
if (tar_level >= cnts.size()) {
// 如果要查询的层级超出了统计范围,则返回0
System.out.println(0);
} else {
// 获取对应层级上对应关键字出现的频次,如果没有出现,则返回0
System.out.println(cnts.get(tar_level).getOrDefault(tar_urlComponent, 0));
}
}
}
Python算法源码
# 访问历史日志的条数
n = int(input())
# 记录各层级上各关键字出现的频次
cnts = []
# 遍历历史日志
for _ in range(n):
# 将日志按照 "/" 分割,注意split函数会将 "/a/b/c" 会分割出数组 ["", "a", "b", "c"],因此a,b,c的层级就是其索引值
urlComponents = input().split("/")
# 遍历url的各层级
for level in range(len(urlComponents)):
urlComponent = urlComponents[level]
# 如果cnts不存在对于层级
if level >= len(cnts):
# 则创建对应层级
cnts.append({})
# 获取对应层级
cnts[level][urlComponent] = cnts[level].get(urlComponent, 0) + 1
# 要查询的给定层级, 要查询的关键字
tar_level, tar_urlComponent = input().split()
tar_level = int(tar_level)
if tar_level >= len(cnts):
# 如果要查询的层级超出了统计范围,则返回0
print(0)
else:
# 获取对应层级上对应关键字出现的频次,如果没有出现,则返回0
print(cnts[tar_level].get(tar_urlComponent, 0))
C算法源码
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX_URL_LENGTH 150
#define MAX_LEVELS 11
typedef struct ListNode {
char urlComponent[11];
int count;
struct ListNode *next;
} ListNode;
ListNode *new_ListNode(char *urlComponent) {
ListNode *node = (ListNode *) malloc(sizeof(ListNode));
strcpy(node->urlComponent, urlComponent);
node->count = 1;
return node;
}
typedef struct LinkedList {
int size;
ListNode *head;
ListNode *tail;
} LinkedList;
LinkedList *new_LinkedList() {
LinkedList *link = (LinkedList *) malloc(sizeof(LinkedList));
link->size = 0;
link->head = NULL;
link->tail = NULL;
return link;
}
void add_LinkedList(LinkedList *link, char *urlComponent) {
ListNode *cur = link->head;
while (cur != NULL) {
if (strcmp(cur->urlComponent, urlComponent) == 0) {
cur->count++;
return;
}
cur = cur->next;
}
ListNode *node = new_ListNode(urlComponent);
node->next = link->head;
link->head = node;
link->size++;
}
int get_LinkedList(LinkedList *link, char *urlComponent) {
ListNode *cur = link->head;
while (cur != NULL) {
if (strcmp(cur->urlComponent, urlComponent) == 0) {
return cur->count;
}
cur = cur->next;
}
return 0;
}
int main() {
// 访问历史日志的条数
int n;
scanf("%d", &n);
getchar();
// 记录各层级上各关键字出现的频次
LinkedList *cnts[MAX_LEVELS] = {NULL};
int cnts_size = 1;
// 遍历历史日志
for (int i = 0; i < n; i++) {
char url[MAX_URL_LENGTH];
gets(url);
// 按照 "/" 分割url,比如 "/a/b/c" ,C语言的strtok函数第一次就会解析出"a",而”a“的层级是1,因此level从1开始计数
int level = 1;
char *token = strtok(url, "/");
while (token != NULL) {
// 如果cnts不存在对于层级
if (level >= cnts_size) {
// 则创建对应层级
cnts[cnts_size++] = new_LinkedList();
}
// 将对应层级上将对应关键字出现次数+1
add_LinkedList(cnts[level], token);
level++;
token = strtok(NULL, "/");
}
}
// 要查询的给定层级
int tar_level;
// 要查询的关键字
char tar_urlComponent[11];
scanf("%d %s", &tar_level, tar_urlComponent);
if (tar_level >= cnts_size) {
// 如果要查询的层级超出了统计范围,则返回0
puts("0");
} else {
// 获取对应层级上对应关键字出现的频次,如果没有出现,则返回0
printf("%dn", get_LinkedList(cnts[tar_level], tar_urlComponent));
}
return 0;
}免责声明: