题目描述
给一个字符串,表示用’,’分开的人名。
然后给定一个字符串,进行快速人名查找,符合要求的输出。
快速人名查找要求︰人名的每个单词的连续前几位能组成给定字符串,一定要用到每个单词。
输入描述
第一行是人名,用’,’分开的人名
第二行是 查找字符串
输出描述
输出满足要求的人名
用例
| 输入 | zhang san,zhang san san zs |
| 输出 | zhang san |
| 说明 | 无 |
| 输入 | zhang san san,zhang an sa,zhang hang,zhang seng,zhang sen a zhas |
| 输出 | zhang an sa,zhang seng |
| 说明 | 无 |
题目解析
本题暂时没有想到更好的解法,只能通过暴力法求解。
我的解题思路如下:
比如人名为:zhang seng,前缀缩写为:zhas
首先将人名字符串按照空格分隔为字符串数组,如Sting parts = ["zhang","san"]
前缀缩写定义为 String abbr = "zhas",用一个start指针指向abbr的被检查的字母,初始时start=0,即指向abbr的第0个字母。
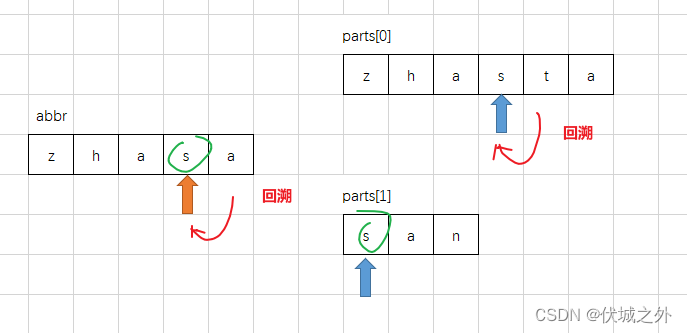
然后按照下图逻辑开始进行人名的每个part的前缀部分和abbr的匹配,匹配逻辑如下图所示:
abbr开头字母必须首先要和parts[0]的开头字母匹配,如果无法匹配否则就表示当前人名无法缩写为abbr。
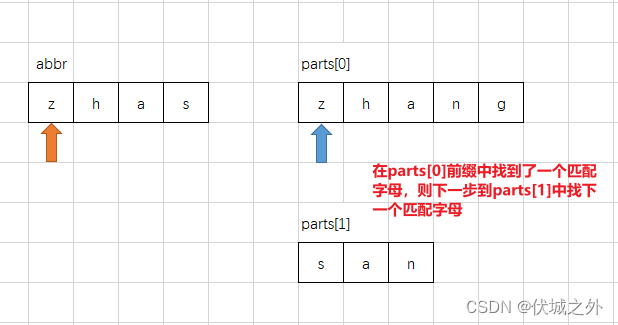
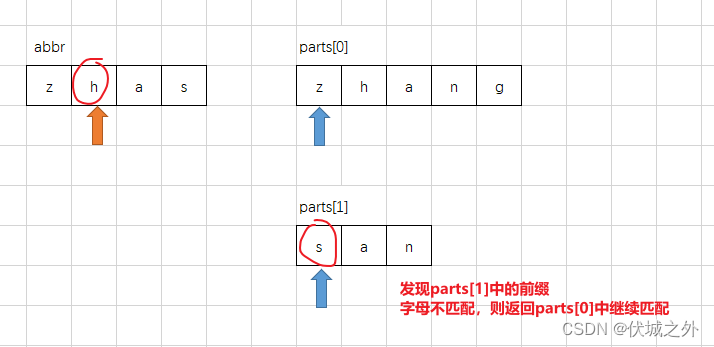
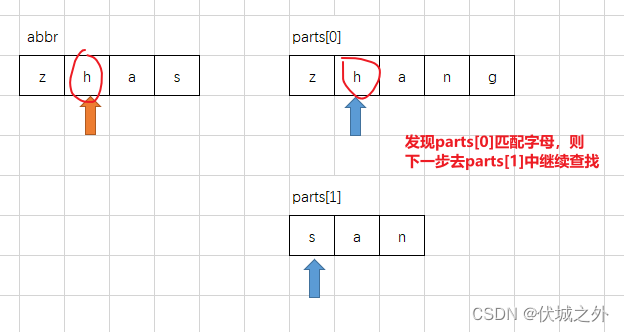
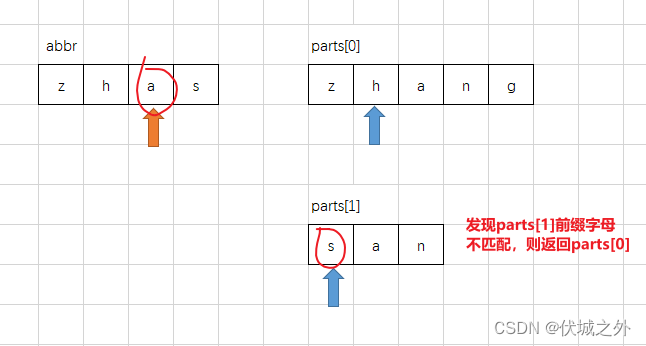
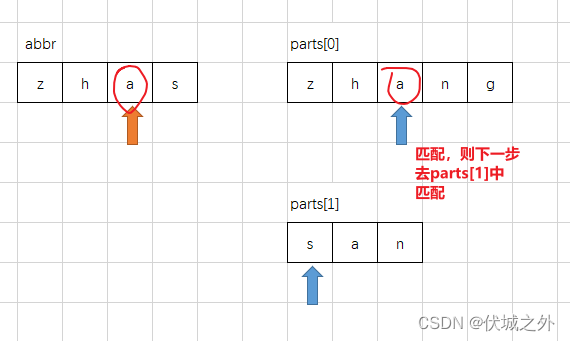
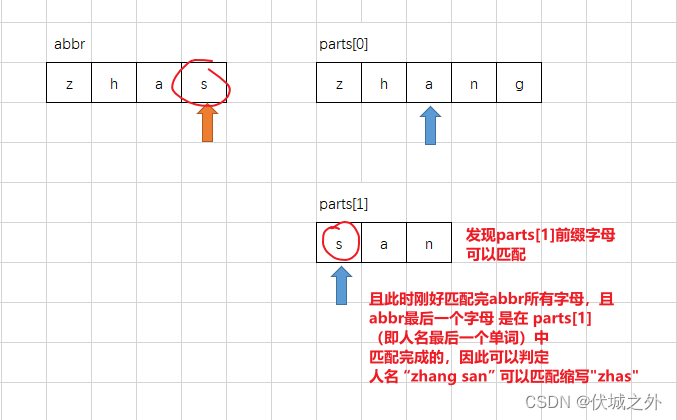
通过上面图示,我们可以发现,parts[0]每匹配到一个abbr字母,就把下一次的匹配权让给了parts[1],这是为什么呢?
因为,这样可以避免abbr的扫描指针的回溯。啥意思呢?
我们看看下面这个例子:
人名:zhasta san
缩写:zhasa
如果优先parts[0]匹配的话,则必然会走到下面这种情况
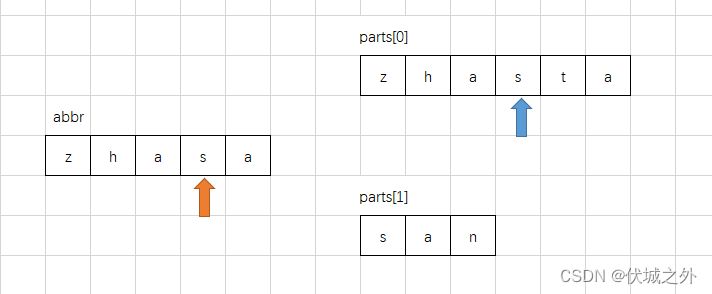
然后下一步匹配,就会出问题
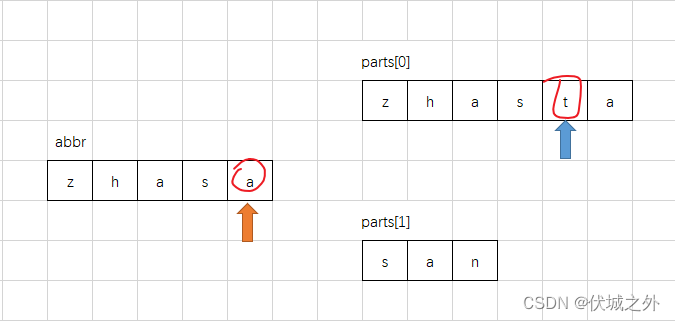
此时,我们就需要进行abbr的扫描指针回溯,然后将匹配权交到parts[1]手上。
可能有人觉得这样匹配速度反而会更快一点,但是如果用例是下面这种呢?
- 人名:zhass san san
- 缩写:zhass
即我们可以在一个part中就完成了缩写匹配,但是题目要求所有的单词part都要使用到,此时我们应该如何回溯呢?
这样的回溯操作逻辑将变得十分复杂,且性能不佳。因此我们需要尽量避免abbr的扫描指针回溯行为。
如果,大家对上面部分都理解了,那么本题差不多就搞定了。
上面例子都是两个part的人名,本题并没有说人名由几个part组成,因此我们无法确定要几重for循环解题,此时只能依赖于回溯递归来帮助我们。具体递归逻辑请看代码。
JavaScript算法源码
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void (async function () {
const names = (await readline()).split(",");
const abbr = await readline();
console.log(getResult(names, abbr));
})();
function getResult(names, abbr) {
const ans = [];
for (let name of names) {
const parts = name.split(" ");
if (parts.length > abbr.length) continue;
if (recursive(parts, 0, abbr, 0)) {
ans.push(name);
}
}
return ans.join(",");
}
/**
*
* @param {*} parts 人名组成
* @param {*} parts_index 人名被匹配的组成部分的索引位置
* @param {*} abbr 人名缩写
* @param {*} abbr_index 缩写被匹配的字符的索引位置
* @returns 当前人名name是否匹配对应缩写abbr
*/
function recursive(parts, parts_index, abbr, abbr_index) {
if (abbr_index >= abbr.length) {
// 如果缩写被匹配完,且人名组成也匹配到最后一个,则说明当前人名可以匹配对应缩写
return parts_index >= parts.length;
}
// 如果缩写尚未匹配完,但是人名组成已经匹配完,则说明当前人名无法匹配对应缩写
if (parts_index >= parts.length) {
return false;
}
const part_name = parts[parts_index];
for (let j = 0; j < part_name.length; j++) {
// 如果当前人名组成部分part_name的第 j 个字符 可以 匹配 缩写abbr的第 abbr_index个字符
if (abbr_index < abbr.length && part_name[j] == abbr[abbr_index]) {
// 为了保证part_name匹配不回退,此时我们将缩写abbr的第abbr_index+1个字符的匹配权优先交给人名的parts_index + 1部分
if (recursive(parts, parts_index + 1, abbr, ++abbr_index)) {
return true;
}
} else {
return false;
}
}
return false;
}
Java算法源码
import java.util.ArrayList;
import java.util.Scanner;
import java.util.StringJoiner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String[] names = sc.nextLine().split(",");
String abbr = sc.nextLine();
System.out.println(getResult(names, abbr));
}
public static String getResult(String[] names, String abbr) {
ArrayList<String> ans = new ArrayList<>();
for (String name : names) {
String[] parts = name.split(" ");
if (parts.length > abbr.length()) continue;
if (recursive(parts, 0, abbr, 0)) {
ans.add(name);
}
}
StringJoiner sj = new StringJoiner(",");
for (String an : ans) {
sj.add(an);
}
return sj.toString();
}
/**
* @param parts 人名组成
* @param parts_index 人名被匹配的组成部分的索引位置
* @param abbr 人名缩写
* @param abbr_index 缩写被匹配的字符的索引位置
* @return 当前人名name是否匹配对应缩写abbr
*/
public static boolean recursive(String[] parts, int parts_index, String abbr, int abbr_index) {
if (abbr_index >= abbr.length()) {
// 如果缩写被匹配完,且人名组成也匹配到最后一个,则说明当前人名可以匹配对应缩写
return parts_index >= parts.length;
}
// 如果缩写尚未匹配完,但是人名组成已经匹配完,则说明当前人名无法匹配对应缩写
if (parts_index >= parts.length) {
return false;
}
String part_name = parts[parts_index];
for (int j = 0; j < part_name.length(); j++) {
// 如果当前人名组成部分part_name的第 j 个字符 可以 匹配 缩写abbr的第 abbr_index个字符
if (abbr_index < abbr.length() && part_name.charAt(j) == abbr.charAt(abbr_index)) {
// 为了保证part_name匹配不回退,此时我们将缩写abbr的第abbr_index+1个字符的匹配权优先交给人名的parts_index + 1部分
if (recursive(parts, parts_index + 1, abbr, ++abbr_index)) {
return true;
}
} else {
return false;
}
}
return false;
}
}
Python算法源码
# 输入获取
names = input().split(",")
abbr = input()
# 通过递归实现人名各部分和缩写的匹配
def recursive(parts, parts_index, abbr_index):
"""
:param parts: 人名组成
:param parts_index: 人名被匹配的组成部分的索引位置
:param abbr_index: 缩写被匹配的字符的索引位置
:return: 当前人名name是否匹配对应缩写abbr
"""
if abbr_index >= len(abbr):
# 如果缩写被匹配完,且人名组成也匹配到最后一个,则说明当前人名可以匹配对应缩写
return parts_index >= len(parts)
# 如果缩写尚未匹配完,但是人名组成已经匹配完,则说明当前人名无法匹配对应缩写
if parts_index >= len(parts):
return False
part_name = parts[parts_index]
for j in range(len(part_name)):
# 如果当前人名组成部分part_name的第 j 个字符 可以 匹配 缩写abbr的第 abbr_index个字符
if abbr_index < len(abbr) and part_name[j] == abbr[abbr_index]:
# 为了保证part_name匹配不回退,此时我们将缩写abbr的第abbr_index+1个字符的匹配权优先交给人名的parts_index + 1部分
abbr_index += 1
if recursive(parts, parts_index + 1, abbr_index):
return True
else:
return False
return False
# 算法入口
def getResult():
ans = []
for name in names:
parts = name.split()
if len(parts) > len(abbr):
continue
if recursive(parts, 0, 0):
ans.append(name)
print(",".join(ans))
# 算法调用
getResult()
免责声明: