题目描述
有一种特殊的加密算法,明文为一段数字串,经过密码本查找转换,生成另一段密文数字串。
规则如下:
- 明文为一段数字串由 0~9 组成
- 密码本为数字 0~9 组成的二维数组
- 需要按明文串的数字顺序在密码本里找到同样的数字串,密码本里的数字串是由相邻的单元格数字组成,上下和左右是相邻的,注意:对角线不相邻,同一个单元格的数字不能重复使用。
- 每一位明文对应密文即为密码本中找到的单元格所在的行和列序号(序号从0开始)组成的两个数宇。
如明文第 i 位 Data[i] 对应密码本单元格为 Book[x][y],则明文第 i 位对应的密文为X Y,X和Y之间用空格隔开。
如果有多条密文,返回字符序最小的密文。
如果密码本无法匹配,返回"error"。
请你设计这个加密程序。
示例1:
密码本:
0 0 2
1 3 4
6 6 4
明文:"3",密文:"1 1"
示例2:
密码本:
0 0 2
1 3 4
6 6 4
明文:"0 3",密文:"0 1 1 1"
示例3:
密码本:
0 0 2 4
1 3 4 6
3 4 1 5
6 6 6 5
明文:"0 0 2 4",密文:"0 0 0 1 0 2 0 3" 和 "0 0 0 1 0 2 1 2",返回字典序最小的"0 0 0 1 0 2 0 3"
明文:"8 2 2 3",密文:"error",密码本中无法匹配
输入描述
第一行输入 1 个正整数 N,代表明文的长度(1 ≤ N ≤ 200)
第二行输入 N 个明文组成的序列 Data[i](0 ≤ Data[i] ≤ 9)
第三行输入 1 个正整数 M,代表密文的长度
接下来 M 行,每行 M 个数,代表密文矩阵
输出描述
输出字典序最小密文,如果无法匹配,输出"error"
用例
| 输入 | 2 0 3 3 0 0 2 1 3 4 6 6 4 |
| 输出 | 0 1 1 1 |
| 说明 | 无 |
| 输入 | 2 0 5 3 0 0 2 1 3 4 6 6 4 |
| 输出 | error |
| 说明 | 找不到 0 5 的序列,返回error |
题目解析
题目关键说明如下:
需要按明文串的数字顺序在密码本里找到同样的数字串,密码本里的数字串是由相邻的单元格数字组成,上下和左右是相邻的
明文第 i 位 Data[i] 对应密码本单元格为 Book[x][y],则明文第 i 位对应的密文为X Y
题目示例3图示
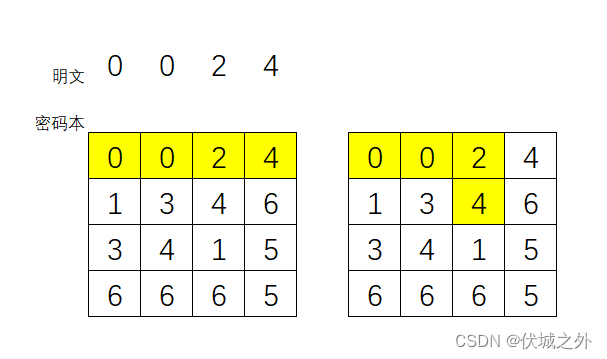
此时密码本多个路径可以对应为明文,分别为:
- (0,0) -> (0,1) -> (0,2) -> (0,3)
- (0,0) -> (0,1) -> (0,2) -> (1,2)
其中0 0 0 1 0 2 0 3字典序更小。
本题可以使用深度优先搜索DFS解题,思路如下:
首先,在密码本矩阵中找到元素值=明文第一个数字的所有元素位置,记录到集合starts中。
然后,遍历starts每一个位置,作为路径探索的起始位置:
此时,深搜方向顺序是有讲究的,需要按照上、左、右、下的顺序依次深搜,因为题目说:
如果有多条密文,返回字符序最小的密文
比如当前位置是 (x,y),而当前位置的上下左右位置的元素值均符合下一个明文数字,那么此时应该选择向哪个方向深搜最优呢?
由于题目要返回字符序最小的密文,对于:
- 上:x-1, y
- 左:x, y-1
- 右:x, y+1
- 下:x+1, y
可以发现,“上”位置的字符序是最小的,因此深搜的优先级应该是:上 > 左 > 右 > 下
这样的话,一旦深搜过程发现符合要求的路径,则必为最优解。
JS算法源码
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void (async function () {
// 明文数字个数
const n = parseInt(await readline());
// 明文
const datas = (await readline()).split(" ").map(Number);
// 密码本矩阵大小
const m = parseInt(await readline());
// 密码本
const secrets = [];
// 记录密码本中元素值等于“明文第一个数字”的所有元素的位置
const starts = [];
for (let i = 0; i < m; i++) {
secrets.push((await readline()).split(" ").map(Number));
for (let j = 0; j < m; j++) {
// 如果密码本(i,j)位置元素指等于明文第一个数字值,则记录(i,j)作为一个出发位置
if (secrets[i][j] == datas[0]) {
starts.push([i, j]);
}
}
}
function getResult() {
// 出发位置(x,y)
for (let [x, y] of starts) {
// used[i][j]用于记录密码本(i,j)元素是否已使用
const used = new Array(m).fill(0).map(() => new Array(m).fill(false));
// 出发点位置元素已使用
used[x][y] = true;
// 记录结果路径各节点位置
const path = [];
// 出发点位置记录
path.push(`${x} ${y}`);
// 开始深搜
if (dfs(x, y, 1, path, used)) {
return path.join(" ");
}
}
return "error";
}
// 上,左,右,下偏移量,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
const offsets = [
[-1, 0],
[0, -1],
[0, 1],
[1, 0],
];
/**
*
* @param {*} x 当前位置横坐标
* @param {*} y 当前位置纵坐标
* @param {*} index datas[index]是将要匹配的明文数字
* @param {*} path 路径
* @param {*} used 密码本各元素使用情况
* @returns 是否找到符合要求的路径
*/
function dfs(x, y, index, path, used) {
// 已找到明文最后一个数字,则找到符合要求的路径
if (index == n) {
return true;
}
// 否则,进行上、左、右、下四个方向偏移,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
for (let [offsetX, offsetY] of offsets) {
// 新位置
const newX = x + offsetX;
const newY = y + offsetY;
// 新位置越界,或者新位置已使用,或者新位置不是目标值,则跳过
if (
newX < 0 ||
newX >= m ||
newY < 0 ||
newY >= m ||
used[newX][newY] ||
secrets[newX][newY] != datas[index]
) {
continue;
}
// 递归进入新位置
path.push(`${newX} ${newY}`);
used[newX][newY] = true;
// 如果当前分支可以找到符合要求的路径,则返回
if (dfs(newX, newY, index + 1, path, used)) {
return true;
}
// 否则,回溯
used[newX][newY] = false;
path.pop();
}
return false;
}
console.log(getResult());
})();
Java算法源码
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Scanner;
import java.util.StringJoiner;
public class Main {
// 明文数字个数
static int n;
// 明文
static int[] datas;
// 密码本矩阵大小
static int m;
// 密码本
static int[][] secrets;
// 上,左,右,下偏移量,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
static int[][] offsets = {{-1, 0}, {0, -1}, {0, 1}, {1, 0}};
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
datas = new int[n];
for (int i = 0; i < n; i++) {
datas[i] = sc.nextInt();
}
// 记录密码本中元素值等于“明文第一个数字”的所有元素的位置
ArrayList<Integer> starts = new ArrayList<>();
m = sc.nextInt();
secrets = new int[m][m];
for (int i = 0; i < m; i++) {
for (int j = 0; j < m; j++) {
secrets[i][j] = sc.nextInt();
// 如果密码本(i,j)位置元素指等于明文第一个数字值,则记录(i,j)作为一个出发位置
if (datas[0] == secrets[i][j]) {
starts.add(i * m + j);
}
}
}
System.out.println(getResult(starts));
}
public static String getResult(ArrayList<Integer> starts) {
for (int start : starts) {
// 出发位置
int x = start / m;
int y = start % m;
// used[i][j]用于记录密码本(i,j)元素是否已使用
boolean[][] used = new boolean[m][m];
// 出发点位置元素已使用
used[x][y] = true;
// 记录结果路径各节点位置
LinkedList<String> path = new LinkedList<>();
// 出发点位置记录
path.add(x + " " + y);
// 开始深搜
if (dfs(x, y, 1, path, used)) {
StringJoiner sj = new StringJoiner(" ");
for (String pos : path) sj.add(pos);
return sj.toString();
}
}
return "error";
}
/**
* @param x 当前位置横坐标
* @param y 当前位置纵坐标
* @param index datas[index]是将要匹配的明文数字
* @param path 路径
* @param used 密码本各元素使用情况
* @return 是否找到符合要求的路径
*/
public static boolean dfs(int x, int y, int index, LinkedList<String> path, boolean[][] used) {
// 已找到明文最后一个数字,则找到符合要求的路径
if (index == n) {
return true;
}
// 否则,进行上、左、右、下四个方向偏移,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
for (int[] offset : offsets) {
// 新位置
int newX = x + offset[0];
int newY = y + offset[1];
// 新位置越界,或者新位置已使用,或者新位置不是目标值,则跳过
if (newX < 0
|| newX >= m
|| newY < 0
|| newY >= m
|| used[newX][newY]
|| secrets[newX][newY] != datas[index]) {
continue;
}
// 递归进入新位置
path.add(newX + " " + newY);
used[newX][newY] = true;
// 如果当前分支可以找到符合要求的路径,则返回
if (dfs(newX, newY, index + 1, path, used)) {
return true;
}
// 否则,回溯
used[newX][newY] = false;
path.removeLast();
}
return false;
}
}
Python算法源码
# 输入获取
n = int(input()) # 明文数字个数
datas = list(map(int, input().split())) # 明文
m = int(input()) # 密码本矩阵大小
secrets = [] # 密码本
# 记录密码本中元素值等于“明文第一个数字”的所有元素的位置
starts = []
for i in range(m):
secrets.append(list(map(int, input().split())))
for j in range(m):
# 如果密码本(i,j)位置元素指等于明文第一个数字值,则记录(i,j)作为一个出发位置
if secrets[i][j] == datas[0]:
starts.append((i, j))
# 上,左,右,下偏移量,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
offsets = ((-1, 0), (0, -1), (0, 1), (1, 0))
def dfs(x, y, index, path, used):
"""
:param x: 当前位置横坐标
:param y: 当前位置纵坐标
:param index: datas[index]是将要匹配的明文数字
:param path: 路径
:param used: 密码本各元素使用情况
:return: 是否找到符合要求的路径
"""
if index == n:
# 已找到明文最后一个数字,则找到符合要求的路径
return True
# 否则,进行上、左、右、下四个方向偏移,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
for offsetX, offsetY in offsets:
# 新位置
newX = x + offsetX
newY = y + offsetY
# 新位置越界,或者新位置已使用,或者新位置不是目标值,则跳过
if newX < 0 or newX >= m or newY < 0 or newY >= m or used[newX][newY] or secrets[newX][newY] != datas[index]:
continue
# 递归进入新位置
path.append(f"{newX} {newY}")
used[newX][newY] = True
# 如果当前分支可以找到符合要求的路径,则返回
if dfs(newX, newY, index + 1, path, used):
return True
# 否则,回溯
used[newX][newY] = False
path.pop()
return False
# 算法入口
def getResult():
# 出发位置(x,y)
for x, y in starts:
# used[i][j]用于记录密码本(i,j)元素是否已使用
used = [[False] * m for _ in range(m)]
# 出发点位置元素已使用
used[x][y] = True
# 记录结果路径各节点位置
# 出发点位置记录
path = [f"{x} {y}"]
# 开始深搜
if dfs(x, y, 1, path, used):
return " ".join(path)
return "error"
# 算法调用
print(getResult())
C算法源码
#include <stdio.h>
#define MAX_SIZE 201
// 明文数字个数
int n;
// 明文
int datas[MAX_SIZE];
// 密码本矩阵大小
int m;
// 密码本
int secrets[MAX_SIZE][MAX_SIZE];
// 记录密码本中元素值等于“明文第一个数字”的所有元素的位置
int starts[MAX_SIZE] = {0};
int starts_size = 0;
// 上,左,右,下偏移量,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
int offsets[4][2] = {{-1, 0},
{0, -1},
{0, 1},
{1, 0}};
/*!
*
* @param x 当前位置横坐标
* @param y 当前位置纵坐标
* @param index datas[index]是将要匹配的明文数字
* @return 是否找到符合要求的路径
*/
int dfs(int x, int y, int index, int path[], int *path_size, int used[][MAX_SIZE]) {
// 已找到明文最后一个数字,则找到符合要求的路径
if (index == n) {
return 1;
}
// 否则,进行上、左、右、下四个方向偏移,注意这里的顺序是有影响的,即下一步偏移后产生的密文的字符序必然是:上 < 左 < 右 < 下
for (int i = 0; i < 4; i++) {
// 新位置
int newX = x + offsets[i][0];
int newY = y + offsets[i][1];
// 新位置越界,或者新位置已使用,或者新位置不是目标值,则跳过
if (newX < 0 || newX >= m || newY < 0 || newY >= m || used[newX][newY] ||
secrets[newX][newY] != datas[index]) {
continue;
}
// 递归进入新位置
path[(*path_size)++] = newX * m + newY;
used[newX][newY] = 1;
// 如果当前分支可以找到符合要求的路径,则返回
if (dfs(newX, newY, index + 1, path, path_size, used)) {
return 1;
}
// 否则,回溯
used[newX][newY] = 0;
(*path_size)--;
}
return 0;
}
void getResult() {
for (int i = 0; i < starts_size; i++) {
// 出发位置
int x = starts[i] / m;
int y = starts[i] % m;
// used[i][j]用于记录密码本(i,j)元素是否已使用
int used[MAX_SIZE][MAX_SIZE] = {0};
// 出发点位置元素已使用
used[x][y] = 1;
// 记录结果路径各节点位置
int path[MAX_SIZE] = {0};
int path_size = 0;
// 出发点位置记录
path[path_size++] = starts[i];
// 开始深搜
if (dfs(x, y, 1, path, &path_size, used)) {
// 找到符合要求的路径,则打印
for (int j = 0; j < path_size; j++) {
int pos = path[j];
printf("%d %d", pos / m, pos % m);
if (j < path_size - 1) {
printf(" ");
}
}
return;
}
}
// 找不到符合要求的路径,则打印error
puts("error");
}
int main() {
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &datas[i]);
}
scanf("%d", &m);
for (int i = 0; i < m; i++) {
for (int j = 0; j < m; j++) {
scanf("%d", &secrets[i][j]);
// 如果密码本(i,j)位置元素指等于明文第一个数字值,则记录(i,j)作为一个出发位置
if (secrets[i][j] == datas[0]) {
starts[starts_size++] = i * m + j;
}
}
}
getResult();
return 0;
}免责声明: