题目描述
有一个考古学家发现一个石碑,但是很可惜,发现时其已经断成多段,原地发现n个断口整齐的石碑碎片。
为了破解石碑内容,考古学家希望有程序能帮忙计算复原后的石碑文字组合数,你能帮忙吗?
输入描述
第一行输入 n
- n表示石碑碎片的个数
第二行依次输入石碑碎片上的文字内容s,共有n组。
输出描述
输出石碑文字的组合(按照升序排列),行末无多余空格。
备注
如果存在石碑碎片内容完全相同,则由于碎片间的顺序变换不影响复原后的碑文内容,即相同碎片间的位置变换不影响组合。
用例
| 输入 | 3 a b c |
| 输出 | abc acb bac bca cab cba |
| 说明 | 当石碑碎片上的内容为“a”,“b”,“c”时,则组合有“abc”,“acb”,“bac”,“bca”,“cab”,“cba” |
| 输入 | 3 a b a |
| 输出 | aab aba baa |
| 说明 | 当石碑碎片上的内容为“a”,“b”,“a”时,则可能的组合有“aab”,“aba”,“baa” |
| 输入 | 3 a b ab |
| 输出 | aabb abab abba baab baba |
| 说明 | 当石碑碎片上的内容为“a”,“b”,“ab”时,则可能的组合有“aabb”,“abab”,“abba”,“baab”,“baba” |
题目解析
本题是全排列求解问题。
关于全排列的求解可以看下:
关于不重复的全排列求解可以看下:
LeetCode – 47 全排列 II_leetcode 全排列2-CSDN博客
本题和leetcode47区别在于:
石碑碎片内容可能是多个字母,比如用例3:
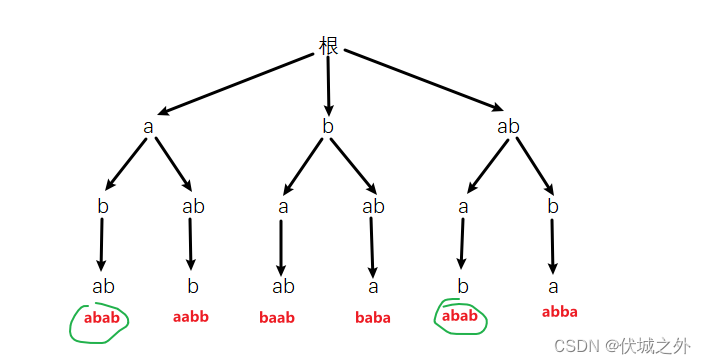
此时树层去重是无法检测出来的,因此我们还需要对求出来的全排列字符串进行一次去重
JS算法源码
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void (async function () {
// 输入获取
const n = parseInt(await readline());
const arr = (await readline()).split(" ");
const res = new Set();
const used = new Array(n).fill(false);
const path = [];
// 排序是为了让相同元素相邻,方便后面树层去重
arr.sort();
dfs(arr, used, path, res);
// 输出石碑文字的组合(按照升序排列)
[...res].sort().forEach((val) => console.log(val));
})();
function dfs(arr, used, path, res) {
if (path.length == arr.length) {
res.add(path.join(""));
return;
}
for (let i = 0; i < arr.length; i++) {
if (used[i]) continue;
// 树层去重
if (i > 0 && arr[i] == arr[i - 1] && !used[i - 1]) continue;
path.push(arr[i]);
used[i] = true;
dfs(arr, used, path, res);
used[i] = false;
path.pop();
}
}
Java算法源码
import java.util.Arrays;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Scanner;
public class Main {
static int n;
static String[] arr;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = Integer.parseInt(sc.nextLine());
arr = sc.nextLine().split(" ");
getResult();
}
public static void getResult() {
// 排序是为了让相同元素相邻,方便后面树层去重
Arrays.sort(arr);
boolean[] used = new boolean[n];
LinkedList<String> path = new LinkedList<>();
HashSet<String> res = new HashSet<>();
dfs(used, path, res);
// 输出石碑文字的组合(按照升序排列)
res.stream().sorted(String::compareTo).forEach(System.out::println);
}
public static void dfs(boolean[] used, LinkedList<String> path, HashSet<String> res) {
if (path.size() == n) {
StringBuilder sb = new StringBuilder();
path.forEach(sb::append);
res.add(sb.toString());
return;
}
for (int i = 0; i < n; i++) {
if (used[i]) continue;
// 树层去重
if (i > 0 && arr[i].equals(arr[i - 1]) && !used[i - 1]) continue;
path.addLast(arr[i]);
used[i] = true;
dfs(used, path, res);
used[i] = false;
path.removeLast();
}
}
}
Python算法源码
# 输入获取
n = int(input())
arr = input().split()
# 全局变量
path = []
used = [False] * n
cache = set()
# 全排列求解
def dfs():
if len(path) == n:
cache.add("".join(path))
return
for i in range(n):
if used[i]:
continue
# 树层去重
if i > 0 and arr[i] == arr[i-1] and not used[i-1]:
continue
path.append(arr[i])
used[i] = True
dfs()
used[i] = False
path.pop()
# 算法入口
def getResult():
# 排序是为了让相同元素相邻,方便后面树层去重
arr.sort()
dfs()
# 输出石碑文字的组合(按照升序排列)
for v in sorted(list(cache)):
print(v)
# 算法调用
getResult()
免责声明:
1、IT资源小站为非营利性网站,全站所有资料仅供网友个人学习使用,禁止商用
2、本站所有文档、视频、书籍等资料均由网友分享,本站只负责收集不承担任何技术及版权问题
3、如本帖侵犯到任何版权问题,请立即告知本站,本站将及时予与删除下载链接并致以最深的歉意
4、本帖部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责
5、一经注册为本站会员,一律视为同意网站规定,本站管理员及版主有权禁止违规用户
6、其他单位或个人使用、转载或引用本文时必须同时征得该帖子作者和IT资源小站的同意
7、IT资源小站管理员和版主有权不事先通知发贴者而删除本文