题目描述
现需要在某城市进行5G网络建设,已经选取N个地点设置5G基站,编号固定为1到N,接下来需要各个基站之间使用光纤进行连接以确保基站能互联互通,不同基站之间假设光纤的成本各不相同,且有些节点之间已经存在光纤相连。
请你设计算法,计算出能联通这些基站的最小成本是多少。
注意:基站的联通具有传递性,比如基站A与基站B架设了光纤,基站B与基站C也架设了光纤,则基站A与基站C视为可以互相联通。
输入描述
第一行输入表示基站的个数N,其中:
- 0 < N ≤ 20
第二行输入表示具备光纤直连条件的基站对的数目M,其中:
- 0 < M < N * (N – 1) / 2
从第三行开始连续输入M行数据,格式为
X Y Z P
其中:
X,Y 表示基站的编号
- 0 < X ≤ N
- 0 < Y ≤ N
- X ≠ Y
Z 表示在 X、Y之间架设光纤的成本
- 0 < Z < 100
P 表示是否已存在光纤连接,0 表示未连接,1表示已连接
输出描述
如果给定条件,可以建设成功互联互通的5G网络,则输出最小的建设成本
如果给定条件,无法建设成功互联互通的5G网络,则输出 -1
用例
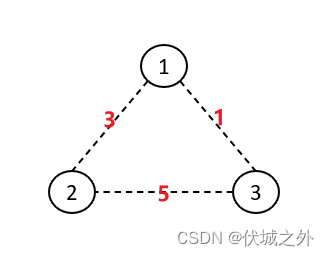
| 输入 | 3 3 1 2 3 0 1 3 1 0 2 3 5 0 |
| 输出 | 4 |
| 说明 | 只需要在1,2以及1,3基站之间铺设光纤,其成本为3+1=4 |
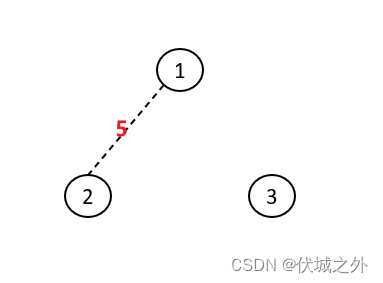
| 输入 | 3 1 1 2 5 0 |
| 输出 | -1 |
| 说明 | 3基站无法与其他基站连接,输出-1 |
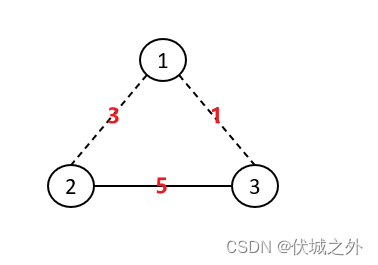
| 输入 | 3 3 1 2 3 0 1 3 1 0 2 3 5 1 |
| 输出 | 1 |
| 说明 | 2,3基站已有光纤相连,只要在1,3基站之间铺设光纤,其成本为1 |
题目解析
(下图中,虚线代表节点之间可以铺设光纤,但是还没有铺设,实线表示已经铺好了)
用例1图示
用例2图示
用例3图示
本题是经典的最小生成树问题
生成树概念
而在了解最小生成树概念前,我们需要先了解生成树的概念:
在无向连通图中,生成树是指包含了全部顶点的极小连通子图。
生成树包含原图全部的n个顶点和n-1条边。(注意,边的数量一定是n-1)
比如下面无向连通图例子:
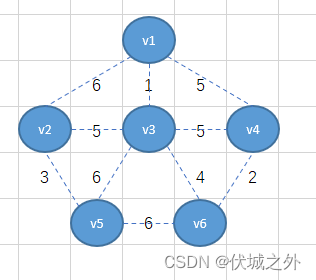
根据生成树概念,我们可以基于上面无向连通图,产生多个生成树,下面举几个生成树例子:
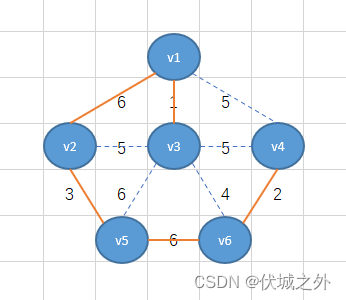
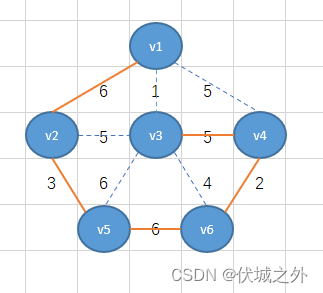
如上图我们用n-1条橙色边连接了n个顶点。这样就从无向连通图中产生了生成树。
为什么生成树只能由n-1条边呢?
因为少一条边,则生成树就无法包含所有顶点。多一条边,则生成树就会形成环。
而生成树最重要的两个特性就是:
1、包含所有顶点
2、无环
最小生成树概念
了解了生成树概念后,我们就可以进一步学习最小生成树了。
我们回头看看无向连通图,可以发现每条边都有权重值,比如v1-v2权重值是6,v3-v6权重值是4。
最小生成树指的是,生成树中n-1条边的权重值之和最小。
那么如何才能准确的找出一个无向连通图的最小生成树呢?
有两种算法:Prim算法和Kruskal算法。
Prim算法是基于顶点找最小生成树。Kruskal是基于边找最小生成树。
Prim算法
首先,我们介绍Prim算法:
我们可以选择无向连通图中的任意一个顶点作为起始点,比如我们选v1顶点为起始点
从v1顶点出发,有三条边,我们选择权重最小的1,即将v1-v3相连
此时我们需要将v1-v3看成一个整体,然后继续找这个整体出发的所有边里面的最小的,
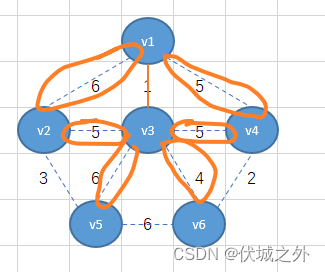
可以发现为最小权重为4,因此,将v3-v6相连
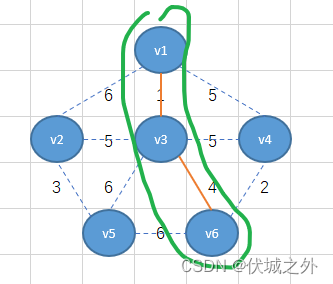
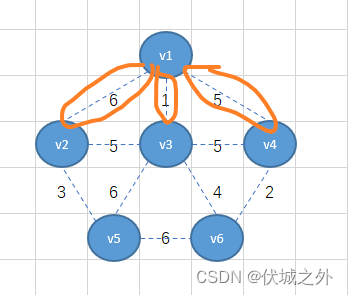
接着将v1-v3-v6看出一个整体,找这个整体出发的所有边里面的最小的,可以找到最小权重2,因此将v6-v4相连
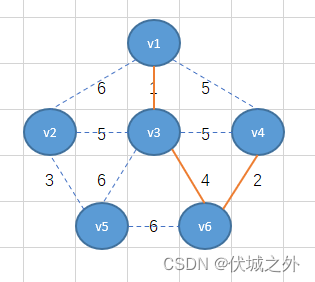
但是接下来,我们会发现,从v1-v3-v6-v4整体出发的所有边里面同时有三个最小权重5,那么该如何选择呢?
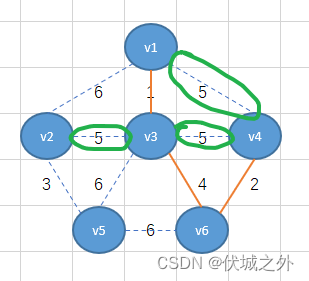
其实不难看出,如果选择v4-v3,或者v4-v1相连,则对应的生成树就形成了环结构,因此就不符合生成树特性了,因此我们只能选择v3-v2。
(注意:如果有多个相同的最小权重边可选,并且都不会产生环结构,则可以选择其中任意一条边,最终得到结果都是最小生成树)
其实,不仅仅在上面遇到相同权重边时,需要判断是否形成环,在前选择每一条边时都需要判断是否形成环,一旦选择的边能够形成环,那么我们就应该舍弃它,选择第二小的权重边,并继续判断。
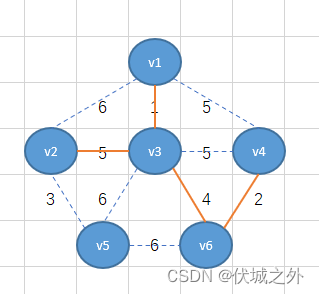
按照上面逻辑,我们可以继续找到v1-v2-v3-v4-v6整体出发所有边中的最小权重边3,即将v2-v5相连,并且连接后不会形成环
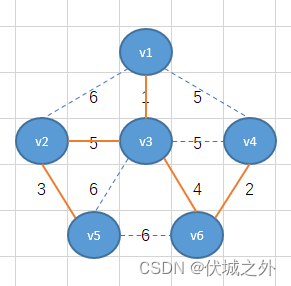
此时选择的边数已经达到了n-1条,因此可以结束逻辑,而现在得到的就是最小生成树。我们可以将这个最小生成数的所有边的权重值之和计算出来为15。
上面这种基于顶点的找最小生成树的方式就是Prim算法。
关于Prim算法具体实现细节请看代码实现,已添加详细注释。
Kruskal算法
接下来介绍Kruskal算法:
Kruskal算法要求我们将所有的边按照权重值升序排序,因此可得:
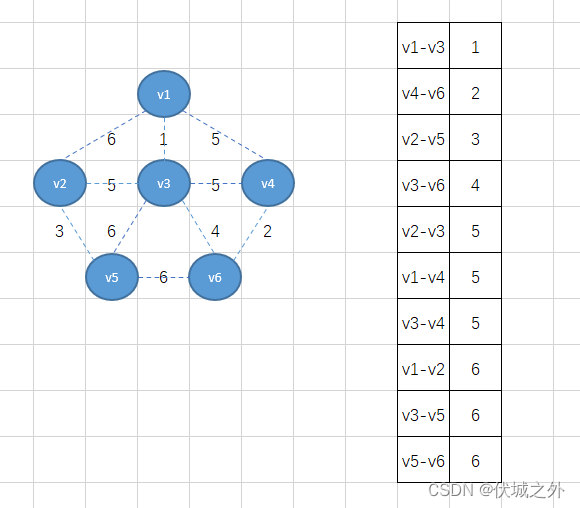
首先,我们将权重最小的边v1-v3加入,得到下图
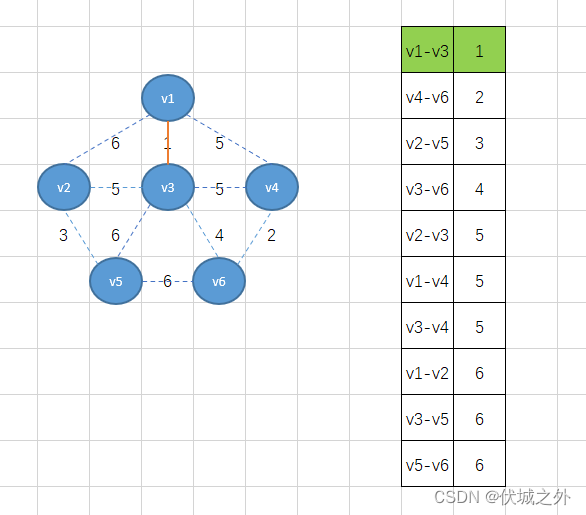
接着将下个最小权重2的边v4-v6加入
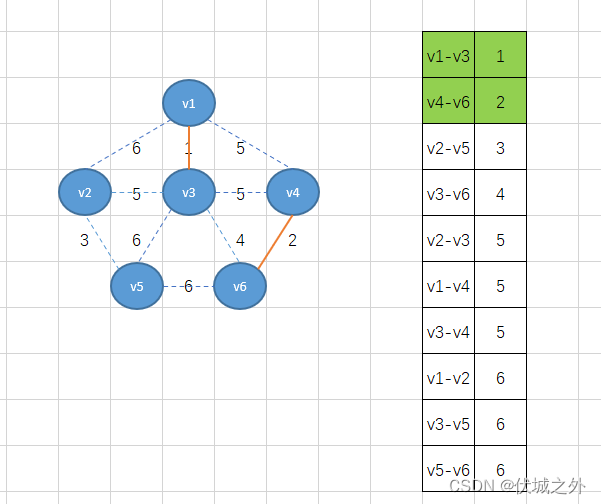
接着继续加最小权重边
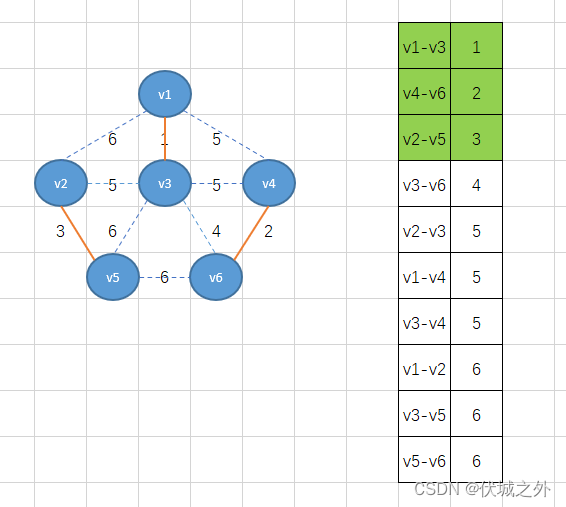
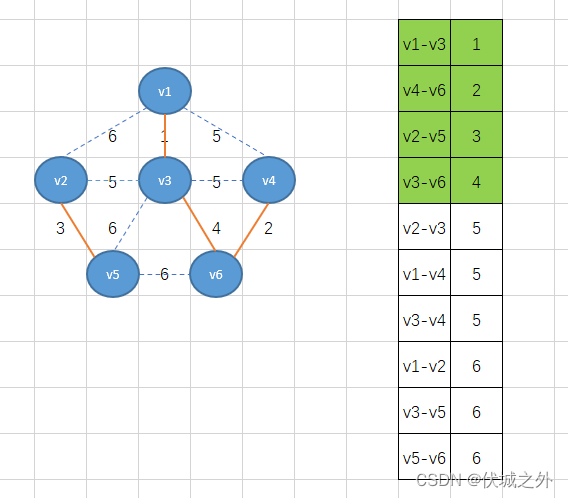
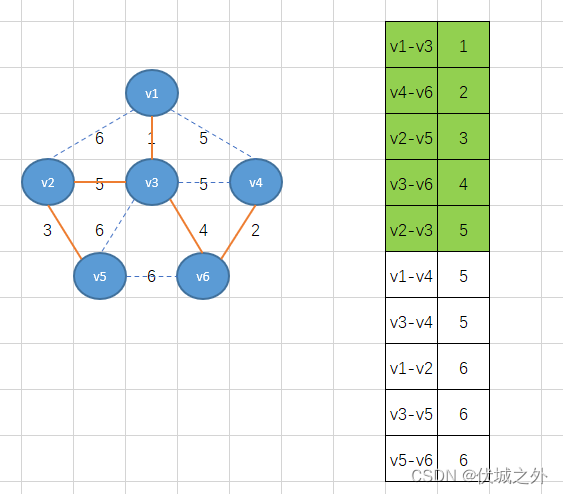
此时边数已经达到n-1,而刚好这个过程中也没有环的形成,因此得到的就是最小生成树。
但是这里有巧合因素在里面,因为最后一步中,最小权重5的边有多条,如果并不是v2-v3排在前面呢,比如是v1-v4呢?
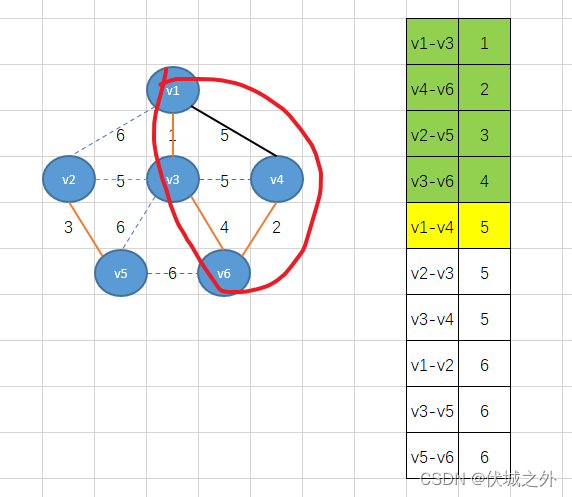
可以发现,形成了环,因此我们应该舍弃这条边,继续找剩下的最小权重边。最后总能找到v2-v3。
那么判断环的存在就是实现上面Prim算法和Kruskal算法的关键点!
其实,生成树就是一个连通分量,初始时,生成树这个连通分量只有一个顶点(Prim),或者两个顶点(Kruskal),后面会不断合入新的顶点进来,来扩大连通分量范围。
而连通分量可以使用并查集表示,
并查集本质就是一个长度为n的数组(n为无向图的顶点数),数组索引值代表图中某个顶点child,数组索引指向的元素值,代表child顶点的祖先顶点father。
初始时,每个child的father都是自己。即初始时,默认有n个连通分量。
比如 arr = [1,1,1,5,5,5] 数组就可以模拟出一个无向图
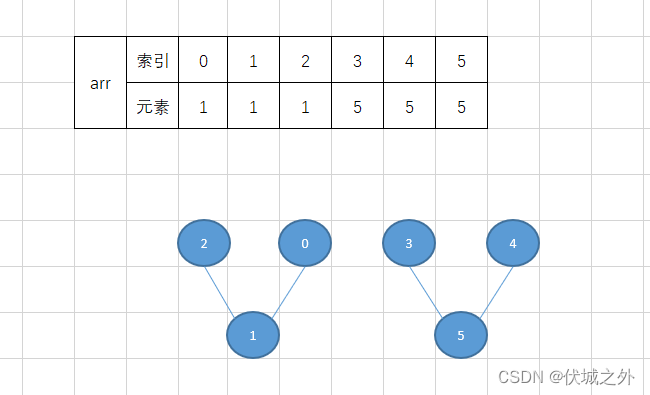
- 0顶点(索引值)的祖先是1顶点(元素值)
- 1顶点(索引值)的祖先是1顶点(元素值)
- 2顶点(索引值)的祖先是1顶点(元素值)
我们可以用father指代一个连通分量。比如上面arr = [1,1,1,5,5,5]就有两个连通分量,分别是father为1的连通分量和father为5的连通分量。
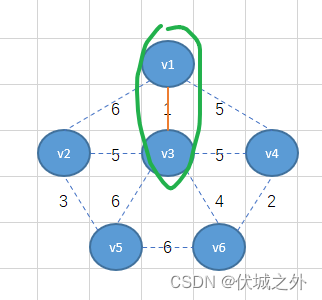
最小生成树中的顶点必然都处于同一个连通分量中,因此每加入一个新的顶点child_new,我们我们就可以看它的father是否已经是连通分量对应的father,如果是,则说明顶点child_new其实已经存在于最小生成树中了,因此就产生了环,比如下面例子:
上面右图绿色部分(对应连通图中橙色实线),则arr变为
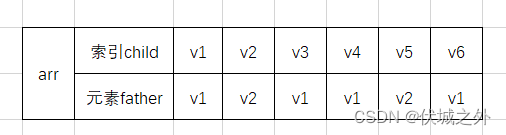
上面右图黄色部分(对应连通图中黑色实线),即v4顶点的father改成v1,但是实际上v4的father已经是v1,那么此时如果再强行加入的话,那么就形成了环。
Prim算法和Kruskal算法的适用场景
Prim算法是基于节点操作的,因此Prim算法适用于节点少,边多的情况
Kruskal算法是基于边操作的,因此Kruskal算法适用于节点多,边少的情况。
本题解析
本题属于最小生成树的变种题,区别于板子题,本题中主要是存在一些已经关联好的节点。
比如下面连通图中,2-3是已经连通好的。
其实处理起来也很简单,对于已经关联了的节点,我们可以认为他们之间的边权为0。
即上图中,2-3虽然边权为5,但是由于已经关联好了,因此可以认为实际边权为0。
这样的话,本题就变成最小生成树的板子题了。
JS算法源码
Prim算法
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void (async function () {
const n = parseInt(await readline()); // 基站数量(节点数)
const m = parseInt(await readline()); // 基站对数量(边数)
// 邻接矩阵, 初始化默认各点之间互不联通,即i-j边权无限大
const graph = new Array(n + 1)
.fill(0)
.map(() => new Array(n + 1).fill(Infinity));
for (let i = 0; i < m; i++) {
const [x, y, z, p] = (await readline()).split(" ").map(Number);
if (p == 0) {
// x-y边权为z
graph[x][y] = z;
graph[y][x] = z;
} else {
// 对应已经联通的两点,可以理解为边权为0
graph[x][y] = 0;
graph[y][x] = 0;
}
}
function prim() {
// 记录最小生成树的边权和
let minWeight = 0;
// inTree[i] 表示 节点i 是否在最小生成树中
const inTree = new Array(n + 1).fill(false);
// 初始时任选一个节点作为最小生成树的初始节点,这里选择节点1
inTree[1] = true;
// 记录最小生成树中点数量
let inTree_count = 1;
// dis[i]表示 节点i 到最小生成树集合 的最短距离
// 初始时,最小生成树集合中只有节点1,因此其他节点到最小生成树的距离,其实就是到节点1的距离
const dis = new Array(n + 1).fill(0).map((_, i) => graph[i][1]);
// 如果最小生成树中点数量达到n个,则结束循环
while (inTree_count < n) {
// 现在我们需要从未纳入最小生成树的点中,找到一个距离最小生成树最近的
let minDis = Infinity; // minDis 记录这个最近距离
let nodeIdx = 0; // idx 记录距离最小生成树minDis个距离的节点
for (let i = 1; i <= n; i++) {
// 从未纳入最小生成树的点中,找到一个距离最小生成树最近的
if (!inTree[i] && dis[i] < minDis) {
minDis = dis[i];
nodeIdx = i;
}
}
// 如果nodeIdx == 0,则说明未纳入最小生成树的这些点到最小生成树的距离都是Integer.MAX_VALUE,即不与最小生成树存在关联
if (nodeIdx == 0) {
// 则说明,当前所有点无法形成最小生成树
return -1;
}
inTree[nodeIdx] = true; // 最小生成树需要纳入最短距离点nodeIdx
inTree_count++; // 最小生成树中点数量+1
minWeight += dis[nodeIdx]; // 更新最小生成树的权重和
// dis[i] 初始时记录的是节点i 到 节点1 的距离(初始的生成树中只有节点1)
// 现在生成树纳入了新节点nodeIdx,则我们需要更新一下dis[i],即有可能某些点到最小生成树中的nodeIdx点距离更近
for (let i = 1; i <= n; i++) {
if (!inTree[i] && graph[nodeIdx][i] < dis[i]) {
// 注意,这是一个累进过程,初始时dis[i]记录的是节点i到节点1的距离,
// 之后,最小生成树纳入新点后,如果节点i到新点的距离更近,则dis[i]就更新为这个更短距离
// 总之,dis[i] 记录的是 节点 i 到最小生成树的最短距离
dis[i] = graph[nodeIdx][i];
}
}
}
return minWeight;
}
console.log(prim());
})();
Kruskal算法
const rl = require("readline").createInterface({ input: process.stdin });
var iter = rl[Symbol.asyncIterator]();
const readline = async () => (await iter.next()).value;
void (async function () {
const n = parseInt(await readline()); // 基站数量(节点数)
const m = parseInt(await readline()); // 基站对数量(边数)
const edges = [];
for (let i = 0; i < m; i++) {
// 边起点, 边终点,边权重,起点和终点是否已关联
const [x, y, z, p] = (await readline()).split(" ").map(Number);
if (p == 0) {
// 起点和终点未关联
edges.push([x, y, z]);
} else {
// 起点和终点已关联,则关联代价实际为0
edges.push([x, y, 0]);
}
}
function kruskal() {
let minWeight = 0;
// 按照边权升序
edges.sort((a, b) => a[2] - b[2]);
const ufs = new UnionFindSet(n + 1);
// 最先遍历出来是边权最小的边
for (const [x, y, z] of edges) {
// 如果edge.from节点 和 edge.to节点 是同一个连通分量(即都在最小生成树中),则此时会产生环
// 因此只有当edge.from节点 和 edge.to节点不在同一个连通分量时,才能合并(纳入最小生成树)
if (ufs.find(x) != ufs.find(y)) {
minWeight += z;
ufs.union(x, y);
// 需要注意的是,上面初始化并查集的节点数为n+1个,因此并查集底层fa数组的长度就是n+1,即索引范围是[0, n],左闭右闭,
// 其中0索引是无用的,1~n索引对应最小生成树中各个节点,如果者n个节点可以变为最小生成树,那么1~n节点会被合并为一个连通分量
// 而0索引虽然无用,但是也会自己形成一个连通分量,因此最终如果能形成最小生成树,则并查集中会有两个连通分量
if (ufs.count == 2) {
return minWeight;
}
}
}
return -1;
}
console.log(kruskal());
})();
// 并查集实现
class UnionFindSet {
constructor(n) {
this.fa = new Array(n).fill(true).map((_, idx) => idx);
this.count = n; // 初始时各站点互不相连,互相独立,因此需要给n个站点发送广播
}
// 查x站点对应的顶级祖先站点
find(x) {
while (x !== this.fa[x]) {
x = this.fa[x];
}
return x;
}
// 合并两个站点,其实就是合并两个站点对应的顶级祖先节点
union(x, y) {
let x_fa = this.find(x);
let y_fa = this.find(y);
if (x_fa !== y_fa) {
// 如果两个站点祖先相同,则在一条链上,不需要合并
this.fa[y_fa] = x_fa; // 合并站点,即让某条链的祖先指向另一条链的祖先
this.count--; // 一旦两个站点合并,则发送广播次数减1
}
}
}
Java算法源码
Prim算法
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 基站数量(节点数)
int m = sc.nextInt(); // 基站对数量(边数)
// 邻接矩阵
int[][] graph = new int[n + 1][n + 1];
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
// 初始化默认各点之间互不联通,即i-j边权无限大
graph[i][j] = Integer.MAX_VALUE;
}
}
for (int i = 0; i < m; i++) {
int x = sc.nextInt();
int y = sc.nextInt();
int z = sc.nextInt();
int p = sc.nextInt();
if (p == 0) {
// x-y边权为z
graph[x][y] = z;
graph[y][x] = z;
} else {
// 对应已经联通的两点,可以理解为边权为0
graph[x][y] = 0;
graph[y][x] = 0;
}
}
System.out.println(prim(graph, n));
}
public static int prim(int[][] graph, int n) {
// 记录最小生成树的边权和
int minWeight = 0;
// inTree[i] 表示 节点i 是否在最小生成树中
boolean[] inTree = new boolean[n + 1];
// 初始时任选一个节点作为最小生成树的初始节点,这里选择节点1
inTree[1] = true;
// 记录最小生成树中点数量
int inTree_count = 1;
// dis[i]表示 节点i 到最小生成树集合 的最短距离
int[] dis = new int[n + 1];
for (int i = 1; i <= n; i++) {
// 初始时,最小生成树集合中只有节点1,因此其他节点到最小生成树的距离,其实就是到节点1的距离
dis[i] = graph[1][i];
}
// 如果最小生成树中点数量达到n个,则结束循环
while (inTree_count < n) {
// 现在我们需要从未纳入最小生成树的点中,找到一个距离最小生成树最近的
// minDis 记录这个最近距离
int minDis = Integer.MAX_VALUE;
// idx 记录距离最小生成树minDis个距离的节点
int nodeIdx = 0;
for (int i = 1; i <= n; i++) {
// 从未纳入最小生成树的点中,找到一个距离最小生成树最近的
if (!inTree[i] && dis[i] < minDis) {
minDis = dis[i];
nodeIdx = i;
}
}
// 如果nodeIdx == 0,则说明未纳入最小生成树的这些点到最小生成树的距离都是Integer.MAX_VALUE,即不与最小生成树存在关联
if (nodeIdx == 0) {
// 则说明,当前所有点无法形成最小生成树
return -1;
}
inTree[nodeIdx] = true; // 最小生成树需要纳入最短距离点nodeIdx
inTree_count++; // 最小生成树中点数量+1
minWeight += dis[nodeIdx]; // 更新最小生成树的权重和
// dis[i] 初始时记录的是节点i 到 节点1 的距离(初始的生成树中只有节点1)
// 现在生成树纳入了新节点nodeIdx,则我们需要更新一下dis[i],即有可能某些点到最小生成树中的nodeIdx点距离更近
for (int i = 1; i <= n; i++) {
if (!inTree[i] && graph[nodeIdx][i] < dis[i]) {
// 注意,这是一个累进过程,初始时dis[i]记录的是节点i到节点1的距离,
// 之后,最小生成树纳入新点后,如果节点i到新点的距离更近,则dis[i]就更新为这个更短距离
// 总之,dis[i] 记录的是 节点 i 到最小生成树的最短距离
dis[i] = graph[nodeIdx][i];
}
}
}
return minWeight;
}
}Kruskal算法
import java.util.Arrays;
import java.util.Scanner;
public class Main {
// 边
static class Edge {
int from; // 边起点
int to; // 边终点
int weight; // 边权重
public Edge(int from, int to, int weight) {
this.from = from;
this.to = to;
this.weight = weight;
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 基站数量(节点数)
int m = sc.nextInt(); // 基站对数量(边数)
Edge[] edges = new Edge[m];
for (int i = 0; i < m; i++) {
int x = sc.nextInt();
int y = sc.nextInt();
int z = sc.nextInt();
int p = sc.nextInt();
// 如果p==1,则可以认为x-y边权为0
edges[i] = new Edge(x, y, p == 0 ? z : 0);
}
System.out.println(kruskal(edges, n));
}
public static int kruskal(Edge[] edges, int n) {
int minWeight = 0;
// 按照边权升序
Arrays.sort(edges, (a, b) -> a.weight - b.weight);
UnionFindSet ufs = new UnionFindSet(n + 1);
// 最先遍历出来是边权最小的边
for (Edge edge : edges) {
// 如果edge.from节点 和 edge.to节点 是同一个连通分量(即都在最小生成树中),则此时会产生环
// 因此只有当edge.from节点 和 edge.to节点不在同一个连通分量时,才能合并(纳入最小生成树)
if (ufs.find(edge.from) != ufs.find(edge.to)) {
minWeight += edge.weight;
ufs.union(edge.from, edge.to);
// 需要注意的是,上面初始化并查集的节点数为n+1个,因此并查集底层fa数组的长度就是n+1,即索引范围是[0, n],左闭右闭,
// 其中0索引是无用的,1~n索引对应最小生成树中各个节点,如果者n个节点可以变为最小生成树,那么1~n节点会被合并为一个连通分量
// 而0索引虽然无用,但是也会自己形成一个连通分量,因此最终如果能形成最小生成树,则并查集中会有两个连通分量
if (ufs.count == 2) {
return minWeight;
}
}
}
return -1;
}
}
// 并查集
class UnionFindSet {
int[] fa;
int count;
public UnionFindSet(int n) {
this.fa = new int[n];
this.count = n;
for (int i = 0; i < n; i++) this.fa[i] = i;
}
public int find(int x) {
if (x != this.fa[x]) {
return (this.fa[x] = this.find(this.fa[x]));
}
return x;
}
public void union(int x, int y) {
int x_fa = this.find(x);
int y_fa = this.find(y);
if (x_fa != y_fa) {
this.fa[y_fa] = x_fa;
this.count--;
}
}
}Python算法源码
Prim算法
import sys
# 输入获取
n = int(input()) # 基站数量(节点数)
m = int(input()) # 基站对数量(边数)
# 邻接矩阵, 初始化默认各点之间互不联通,即i-j边权无限大
graph = [[sys.maxsize for _ in range(n + 1)] for _ in range(n + 1)]
for _ in range(m):
x, y, z, p = map(int, input().split())
if p == 0:
# x-y边权为z
graph[x][y] = z
graph[y][x] = z
else:
# 对应已经联通的两点,可以理解为边权为0
graph[x][y] = 0
graph[y][x] = 0
# Prim算法
def prim():
# 记录最小生成树的边权和
minWeight = 0
# inTree[i] 表示 节点i 是否在最小生成树中
inTree = [False] * (n + 1)
# 初始时任选一个节点作为最小生成树的初始节点,这里选择节点1
inTree[1] = True
# 记录最小生成树中点数量
inTree_count = 1
# dis[i]表示 节点i 到最小生成树集合 的最短距离
# 初始时,最小生成树集合中只有节点1,因此其他节点到最小生成树的距离,其实就是到节点1的距离
dis = [0] * (n + 1)
for i in range(1, n + 1):
dis[i] = graph[1][i]
# 如果最小生成树中点数量达到n个,则结束循环
while inTree_count < n:
# 现在我们需要从未纳入最小生成树的点中,找到一个距离最小生成树最近的
minDis = sys.maxsize # minDis 记录这个最近距离
nodeIdx = 0 # idx 记录距离最小生成树minDis个距离的节点
for i in range(1, n+1):
# 从未纳入最小生成树的点中,找到一个距离最小生成树最近的
if not inTree[i] and dis[i] < minDis:
minDis = dis[i]
nodeIdx = i
# 如果nodeIdx == 0,则说明未纳入最小生成树的这些点到最小生成树的距离都是Integer.MAX_VALUE,即不与最小生成树存在关联
if nodeIdx == 0:
# 则说明,当前所有点无法形成最小生成树
return -1
inTree[nodeIdx] = True # 最小生成树需要纳入最短距离点nodeIdx
inTree_count += 1 # 最小生成树中点数量+1
minWeight += dis[nodeIdx] # 更新最小生成树的权重和
# dis[i] 初始时记录的是节点i 到 节点1 的距离(初始的生成树中只有节点1)
# 现在生成树纳入了新节点nodeIdx,则我们需要更新一下dis[i],即有可能某些点到最小生成树中的nodeIdx点距离更近
for i in range(1, n+1):
if not inTree[i] and graph[nodeIdx][i] < dis[i]:
# 注意,这是一个累进过程,初始时dis[i]记录的是节点i到节点1的距离,
# 之后,最小生成树纳入新点后,如果节点i到新点的距离更近,则dis[i]就更新为这个更短距离
# 总之,dis[i] 记录的是 节点 i 到最小生成树的最短距离
dis[i] = graph[nodeIdx][i]
return minWeight
# 算法调用
print(prim())
Kruskal算法
# 并查集实现
class UnionFindSet:
def __init__(self, n):
self.fa = [i for i in range(n)]
self.count = n
def find(self, x):
if x != self.fa[x]:
self.fa[x] = self.find(self.fa[x])
return self.fa[x]
return x
def union(self, x, y):
x_fa = self.find(x)
y_fa = self.find(y)
if x_fa != y_fa:
self.fa[y_fa] = x_fa
self.count -= 1
# 输入获取
n = int(input()) # 基站数量(节点数)
m = int(input()) # 基站对数量(边数)
edges = []
for _ in range(m):
# 边起点,边终点,边权重(起点和终点关联代价),起点是否已和终点关联
x, y, z, p = map(int, input().split())
if p == 0:
# 起点和终点未关联
edges.append([x, y, z])
else:
# 起点和终点已关联,则实际关联代价为0
edges.append([x, y, 0])
# kruskal算法
def kruskal():
minWeight = 0
# 按照边权升序
edges.sort(key=lambda x: x[2])
ufs = UnionFindSet(n+1)
# 最先遍历出来是边权最小的边
for x, y, z in edges:
# 如果x节点 和 y节点 是同一个连通分量(即都在最小生成树中),则此时会产生环
# 因此只有当x节点 和 y节点不在同一个连通分量时,才能合并(纳入最小生成树)
if ufs.find(x) != ufs.find(y):
minWeight += z
ufs.union(x, y)
# 需要注意的是,上面初始化并查集的节点数为n+1个,因此并查集底层fa数组的长度就是n+1,即索引范围是[0, n],左闭右闭,
# 其中0索引是无用的,1~n索引对应最小生成树中各个节点,如果者n个节点可以变为最小生成树,那么1~n节点会被合并为一个连通分量
# 而0索引虽然无用,但是也会自己形成一个连通分量,因此最终如果能形成最小生成树,则并查集中会有两个连通分量
if ufs.count == 2:
return minWeight
return -1
# 算法入口
print(kruskal())
C算法源码
Prim算法
#include <stdio.h>
#include <limits.h>
int n, m; // 基站数量(节点数),基站对数量(边数)
int graph[21][21]; // 邻接矩阵
int prim() {
// 记录最小生成树的边权和
int minWeight = 0;
// inTree[i] 表示 节点i 是否在最小生成树中
int inTree[21] = {0};
// 初始时任选一个节点作为最小生成树的初始节点,这里选择节点1
inTree[1] = 1;
// 记录最小生成树中点数量
int inTree_count = 1;
// dis[i]表示 节点i 到最小生成树集合 的最短距离
int dis[21];
for (int i = 1; i <= n; i++) {
// 初始时,最小生成树集合中只有节点1,因此其他节点到最小生成树的距离,其实就是到节点1的距离
dis[i] = graph[1][i];
}
// 如果最小生成树中点数量达到n个,则结束循环
while (inTree_count < n) {
// 现在我们需要从未纳入最小生成树的点中,找到一个距离最小生成树最近的
int minDis = INT_MAX; // minDis 记录这个最近距离
int nodeIdx = 0; // idx 记录距离最小生成树minDis个距离的节点
for (int i = 1; i <= n; i++) {
// 从未纳入最小生成树的点中,找到一个距离最小生成树最近的
if (!inTree[i] && dis[i] < minDis) {
minDis = dis[i];
nodeIdx = i;
}
}
// 如果nodeIdx == 0,则说明未纳入最小生成树的这些点到最小生成树的距离都是Integer.MAX_VALUE,即不与最小生成树存在关联
if (nodeIdx == 0) {
// 则说明,当前所有点无法形成最小生成树
return -1;
}
inTree[nodeIdx] = 1; // 最小生成树需要纳入最短距离点nodeIdx
inTree_count++; // 最小生成树中点数量+1
minWeight += dis[nodeIdx]; // 更新最小生成树的权重和
// dis[i] 初始时记录的是节点i 到 节点1 的距离(初始的生成树中只有节点1)
// 现在生成树纳入了新节点nodeIdx,则我们需要更新一下dis[i],即有可能某些点到最小生成树中的nodeIdx点距离更近
for (int i = 1; i <= n; i++) {
if (!inTree[i] && graph[nodeIdx][i] < dis[i]) {
// 注意,这是一个累进过程,初始时dis[i]记录的是节点i到节点1的距离,
// 之后,最小生成树纳入新点后,如果节点i到新点的距离更近,则dis[i]就更新为这个更短距离
// 总之,dis[i] 记录的是 节点 i 到最小生成树的最短距离
dis[i] = graph[nodeIdx][i];
}
}
}
return minWeight;
}
int main() {
scanf("%d %d", &n, &m);
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
// 初始化默认各点之间互不联通,即i-j边权无限大
graph[i][j] = INT_MAX;
}
}
for (int i = 0; i < m; i++) {
int x, y, z, p;
scanf("%d %d %d %d", &x, &y, &z, &p);
if (p == 0) {
// x-y边权为z
graph[x][y] = z;
graph[y][x] = z;
} else {
// 对应已经联通的两点,可以理解为边权为0
graph[x][y] = 0;
graph[y][x] = 0;
}
}
printf("%dn", prim());
return 0;
}Kruskal算法
#include <stdio.h>
#include <stdlib.h>
/** 并查集定义 **/
typedef struct {
int *fa;
int count;
} UFS;
UFS *new_UFS(int n) {
UFS *ufs = (UFS *) malloc(sizeof(UFS));
ufs->fa = (int *) malloc(sizeof(int) * n);
for (int i = 0; i < n; i++) {
ufs->fa[i] = i;
}
ufs->count = n;
return ufs;
}
int find_UFS(UFS *ufs, int x) {
if (x != ufs->fa[x]) {
ufs->fa[x] = find_UFS(ufs, ufs->fa[x]);
return ufs->fa[x];
}
return x;
}
void union_UFS(UFS *ufs, int x, int y) {
int x_fa = find_UFS(ufs, x);
int y_fa = find_UFS(ufs, y);
if (x_fa != y_fa) {
ufs->fa[y_fa] = x_fa;
ufs->count--;
}
}
/*** 边定义 ***/
typedef struct Edge {
int from; // 边起点
int to; // 边终点
int weight; // 边权重
} Edge;
int n, m;
Edge *edges;
int cmp(const void* a, const void* b) {
return ((Edge*) a)->weight - ((Edge*) b)->weight;
}
int kruskal() {
int minWeight = 0;
// 按照边权升序
qsort(edges, m, sizeof(Edge), cmp);
UFS* ufs = new_UFS(n + 1);
// 最先遍历出来是边权最小的边
for(int i=0; i<m; i++) {
int x = edges[i].from;
int y = edges[i].to;
int z = edges[i].weight;
// 如果edge.from节点 和 edge.to节点 是同一个连通分量(即都在最小生成树中),则此时会产生环
// 因此只有当edge.from节点 和 edge.to节点不在同一个连通分量时,才能合并(纳入最小生成树)
if(find_UFS(ufs, x) != find_UFS(ufs, y)) {
minWeight += z;
union_UFS(ufs, x, y);
// 需要注意的是,上面初始化并查集的节点数为n+1个,因此并查集底层fa数组的长度就是n+1,即索引范围是[0, n],左闭右闭,
// 其中0索引是无用的,1~n索引对应最小生成树中各个节点,如果者n个节点可以变为最小生成树,那么1~n节点会被合并为一个连通分量
// 而0索引虽然无用,但是也会自己形成一个连通分量,因此最终如果能形成最小生成树,则并查集中会有两个连通分量
if(ufs->count == 2) {
return minWeight;
}
}
}
return -1;
}
int main() {
scanf("%d %d", &n, &m);
edges = (Edge*) malloc(sizeof(Edge) * m);
for (int i = 0; i < m; i++) {
int x, y, z, p;
scanf("%d %d %d %d", &x, &y, &z, &p);
edges[i].from = x;
edges[i].to = y;
if(p == 0) {
edges[i].weight = z;
} else {
// 如果p==1,则可以认为x-y边权为0
edges[i].weight = 0;
}
}
printf("%dn", kruskal());
return 0;
}免责声明: